自注意力
概述
The animal didn't cross the street because it was too tired.
可以通过自注意力机制知道这里的it指代测是前面的animal,即当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中的其他位置以寻找有助于更好地编码该单词的线索。
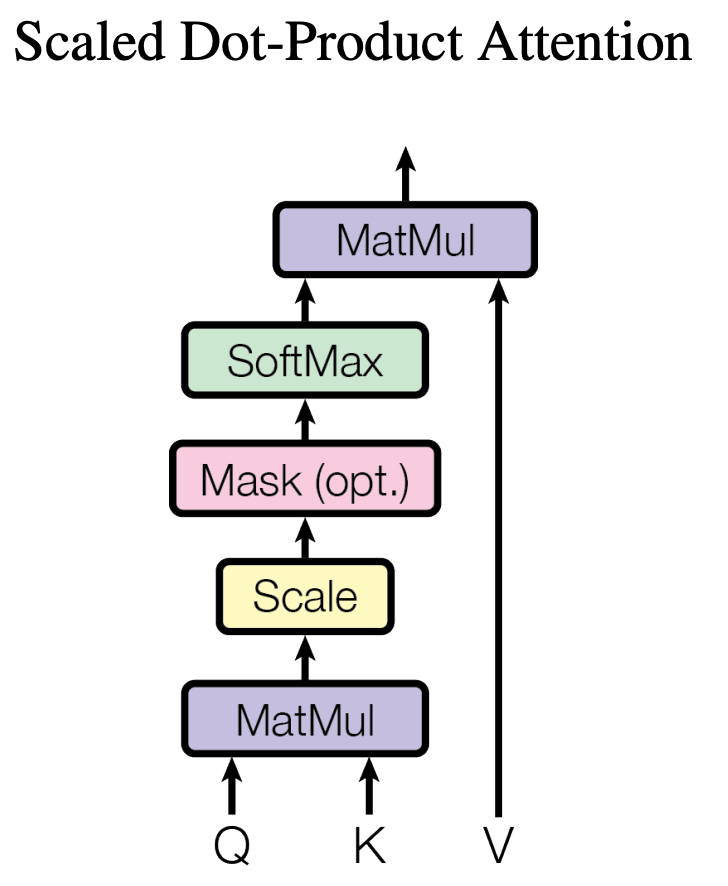
自注意力-向量实现(解释说明用):
输入:embedding;
输出:发送到前馈神经网络里的向量;
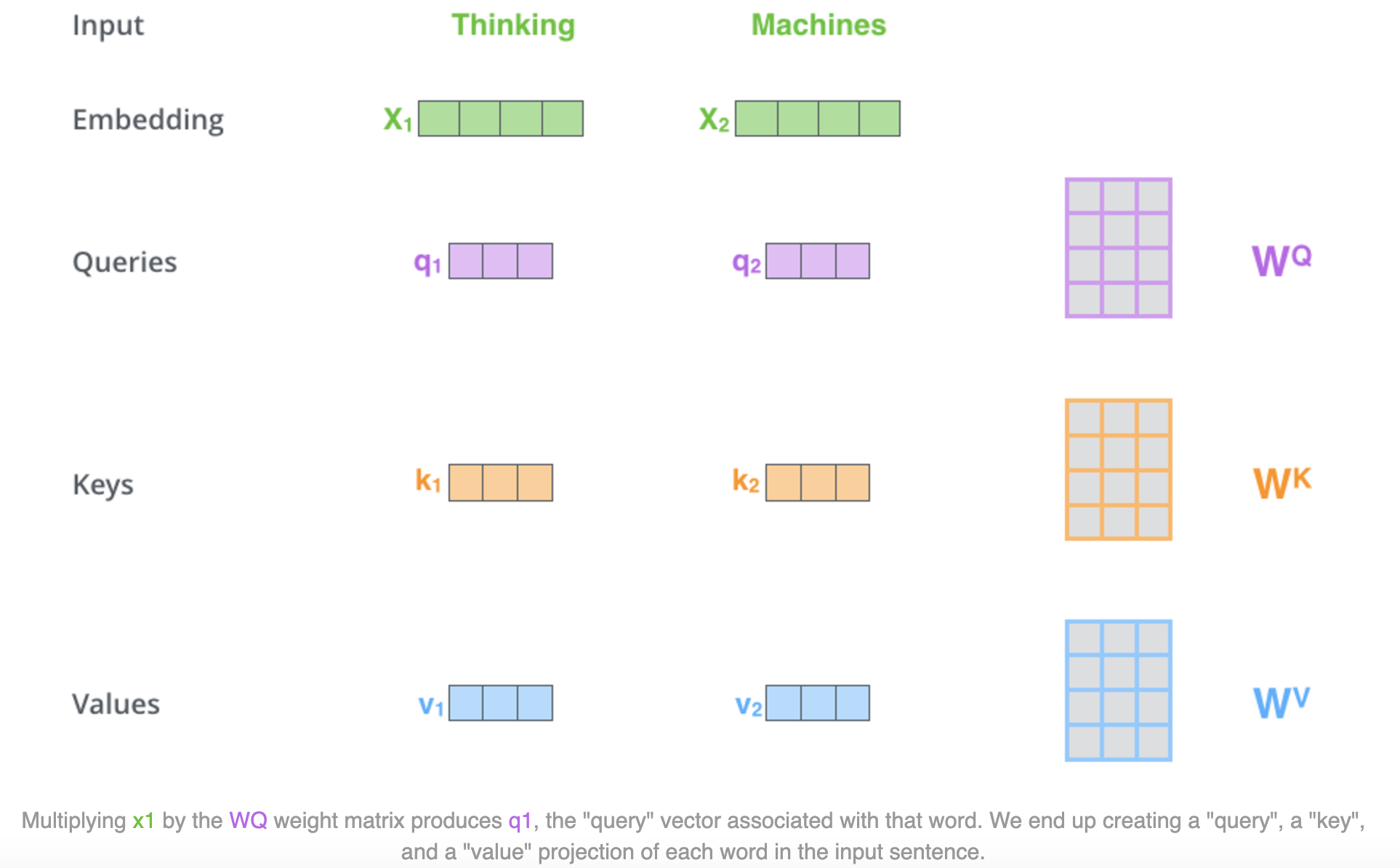
1、第一步: 从每个编码器的输入向量(在本例中为每个单词的嵌入)乘以在训练过程中训练的三个QKV矩阵来分别创建一个查询Q向量、一个键K向量和一个值V向量。
请注意,这些新向量的维度小于嵌入向量,可以使多头注意力的计算(大部分)保持恒定。
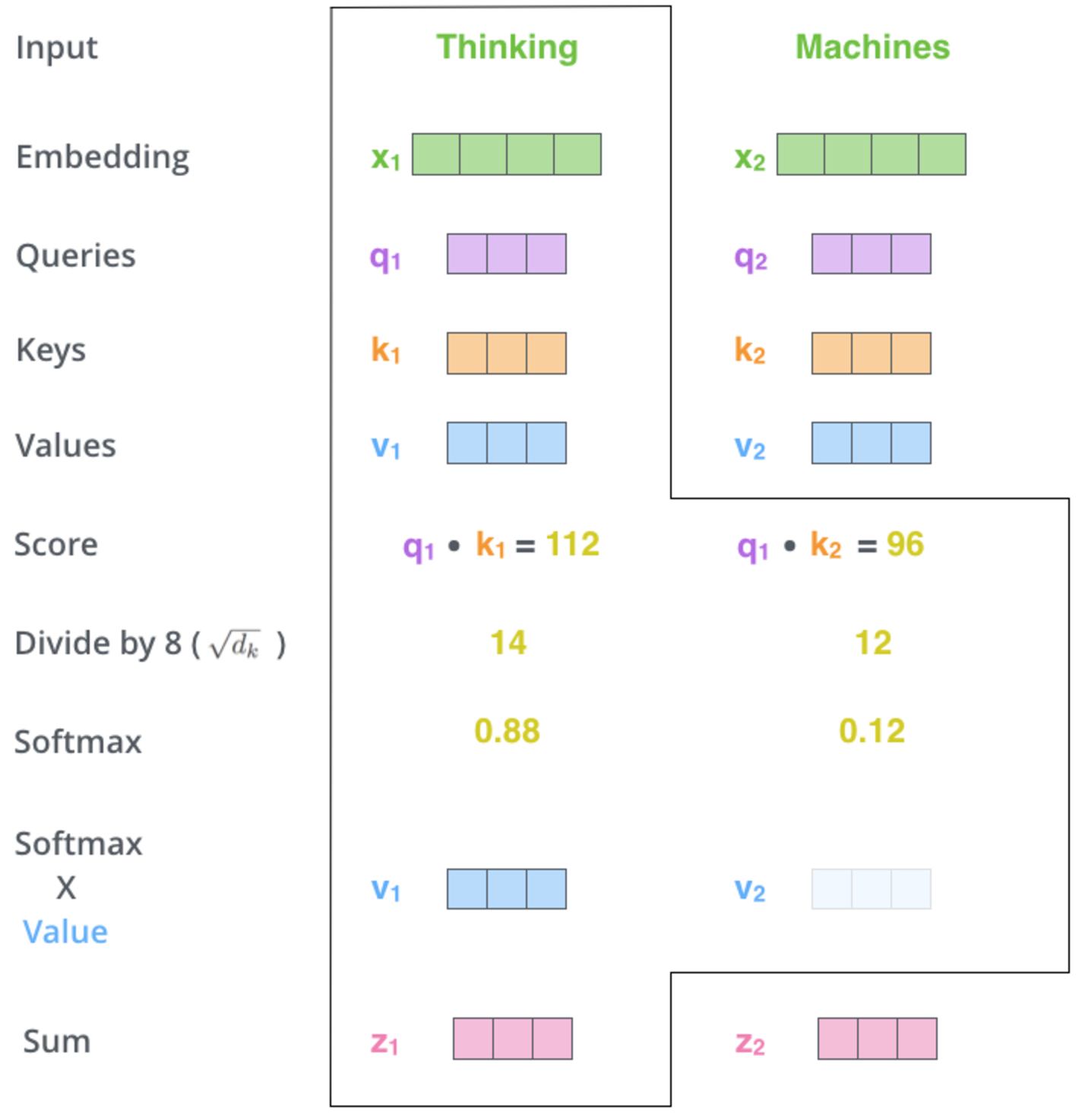
2、第二步:通过==当前单词的Q向量和其他要评分单词的k向量点积==来计算分数。
在某个位置对单词进行编码时,分数决定了对输入句子的其他部分的关注程度。 如果处理位置 #1 中单词thinking的自注意力,第一个分数将是 q1 和 k1 的点积。第二个分数是 q1 和 k2 的点积。
3、第三步:将分数除以 $\sqrt{d_k}$
论文中使用的k向量维度的平方根 – $\sqrt{64}=8$。这里可能还有其他可能的值,但这是默认值。多头注意力的时候通常用k向量维度除头数开方。
#Q:Transforemer除以d_k的原因? Transformer中除以$\sqrt{d_k}$的原因是:缩放点积结果,防止softmax的梯度消失,保持梯度的稳定性;
具体来说,向量点积结果非常大就会进入softmax的饱和区,从而使得梯度接近于0。
4、第四步:Softmax输出
[[激活函数#Softmax|Softmax]] 对分数进行归一化,使它们全部为正值并且加起来为 1。softmax分数决定了每个单词在这个位置上的表达量。
5、第五步:将每个v向量乘以对应位置的softmax 分数(准备将它们相加)。
保持想要关注的单词的值完整,并淹没不相关的单词(例如,通过将它们乘以 0.001 这样的小数字)。
6、第六步:对加权V向量求和。
这会在该位置(第一个单词)产生自注意力层的输出。
自注意力-矩阵实现:
第一步:计算Q、K和V矩阵。通过将Embedding打包到矩阵 X 中,并将其乘以我们训练过的权重矩阵(WQ、WK、WV)来实现。
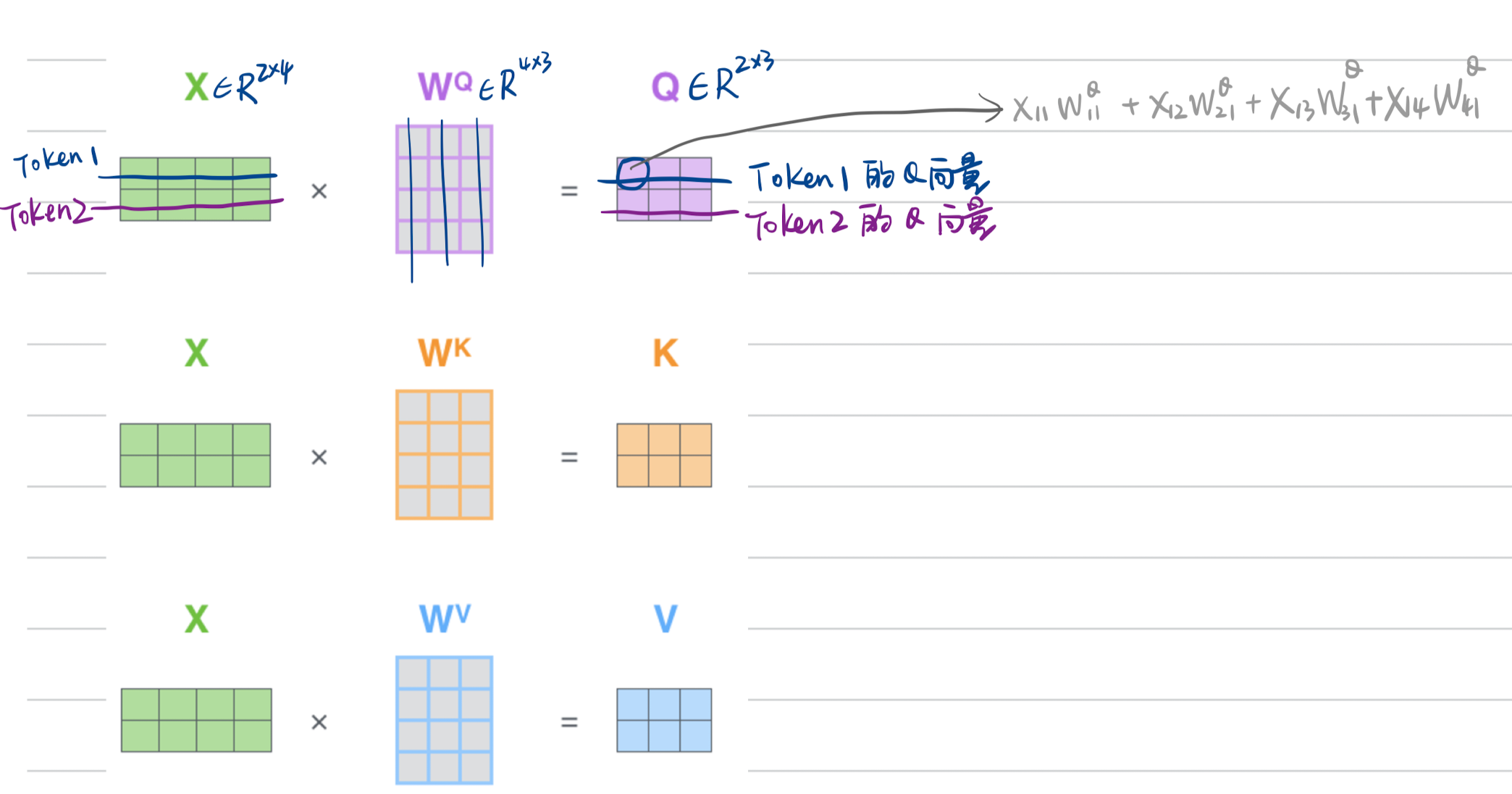
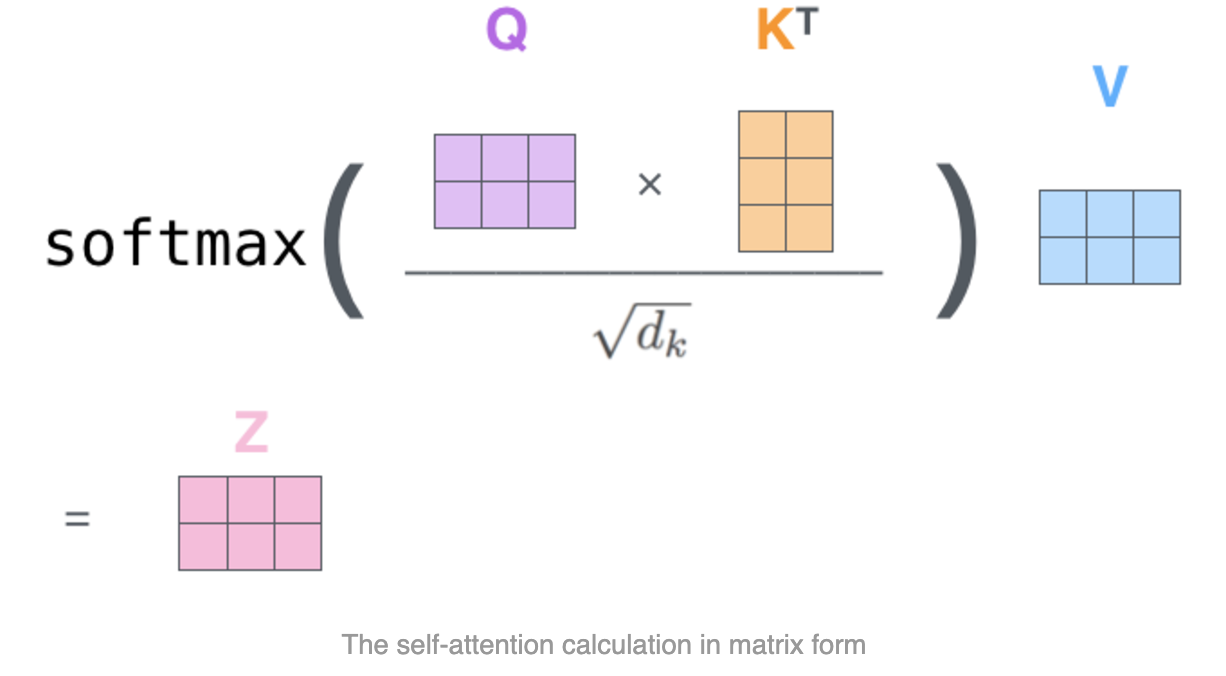
第二步:计算自注意力层的输出。通过下面一个公式解决;
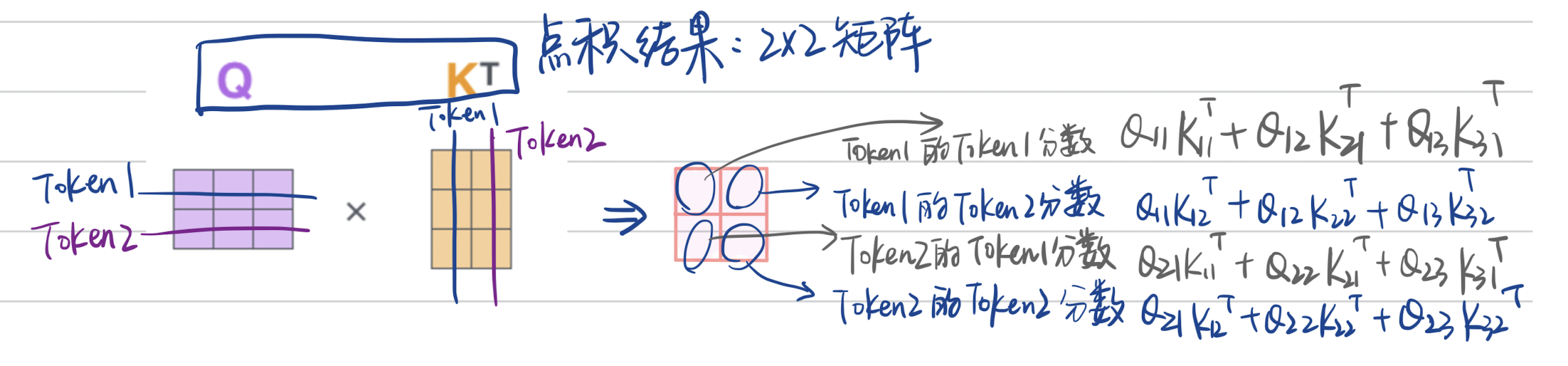
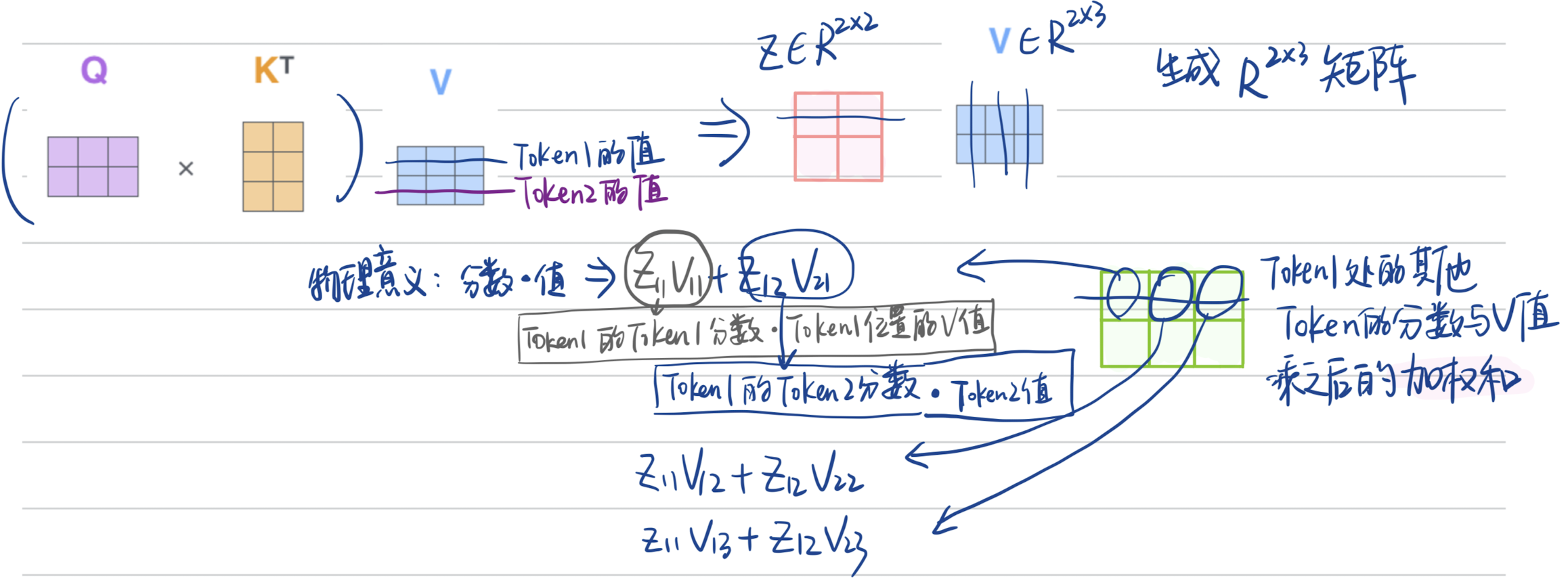
解析,X的第一行是一个embedding,矩阵乘法之后,Q的第1行包含了X第1个embedding信息,一一对应;那么Q和$K^T$的点积,生成的结果是$2\times2$的矩阵,第1行就是第1个embedding和K中第2、3embedding的分数;处以$\sqrt{d_k}$;经过softmax之后,乘以V;
- 公式解析:
- Q和$K^T$ 的点积:返回一个Token数量($2\times 2$)维度的方阵;
- 点积结果乘V:得到注意力分数与V值的乘积的加权和;
- Q和$K^T$ 的点积:返回一个Token数量($2\times 2$)维度的方阵;
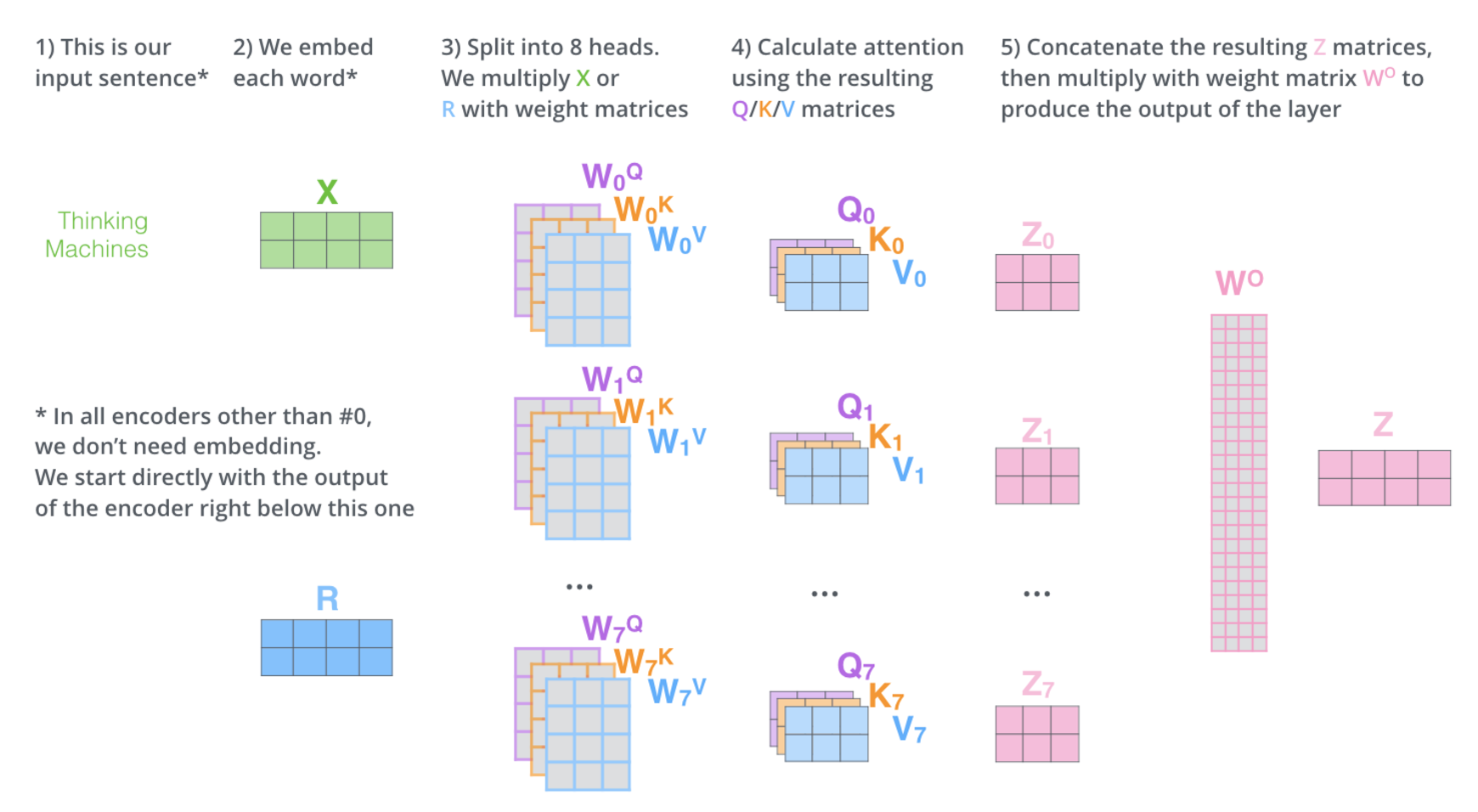
多头注意力
多头就是将输入X分别乘以不同的权重矩阵,得到不同的8个Z矩阵;
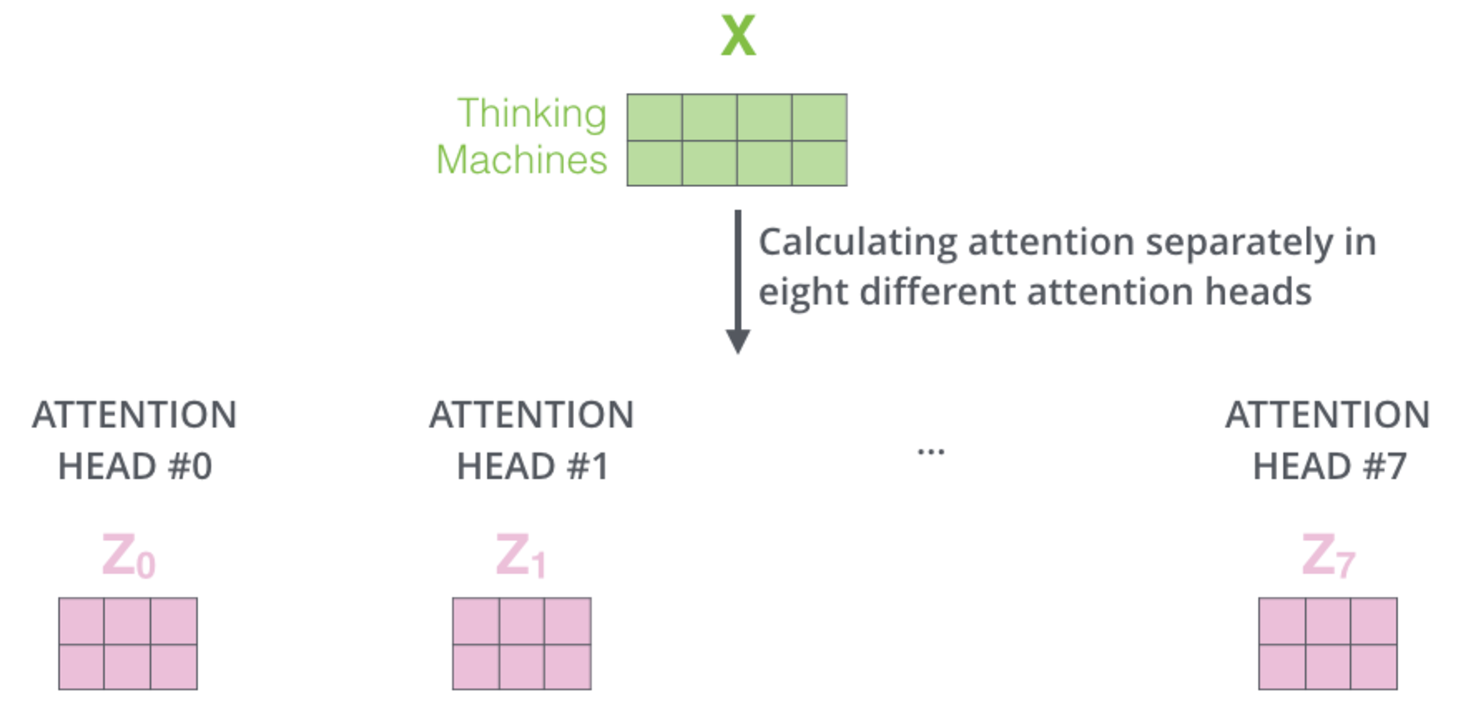
#多头拼接? 为了输入前馈层,将8个Z矩阵拼接成一个矩阵。

最终效果:
可视化效果如图,一个token it_在第5层的8个头的注意力得分不一样。

如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !